概要
動画を自動で吹き替えしてくれるOpen-Dubbingというツールを試してみた。 この記事ではOpen-Dubbingの概要と使い方を説明し、自作したラッパースクリプトを紹介する。 自分の環境でとりあえず動かせるようになったが、性能には不満がある。 実行してみた結果の音声サンプルも載せて、使用感を伝えたい。
背景
以前から英語圏の動画やPodcastをなんとか効率的に視聴できないかと色々なことを試してきた。 文字起こしや字幕があるコンテンツは多いが、ちょっと見るハードルが高い。 目を占有されるのは許容できない程度にどうでもいいコンテンツが多いし、耳だけ使える時間は比較的多いので、できれば耳で聞き流したい。 たとえばトランプ大統領がいろんなPodcastに出てるらしいので一回聞いてみたいが、スマホを眼前に構えて字幕を追いながら聞くほどではない。 自分がネイティブの英語を聞き取れれば何も問題はないが、残念ながら耳だけで有用な情報を正確に拾えるほどのリスニング力がない…… 最近だとmp3ファイルをNotebookLMに取り込ませて、「Podcast生成機能」で短い要約を聞いたりしていた。 しかしそれでは取りこぼすものが多い。
ところで、最近Youtubeを見ていると「オートダビング版」という表示のある動画を見かけるようになった。 ……あらためて探すと見当たらない。英語圏で不人気すぎて表示されなくなったのかもしれない。まあとにかくそういう表示が出ていた時期があった。 テレビ番組の録画をDVD等に焼く「ダビング」のことかと思って何のことだろうと不思議に感じたが、要するに"auto-dubbing"、つまり自動吹き替え版のことだった。 このブログを書くにあたって調べてみたが、前者の方の「ダビング」も同じ"dubbing"という単語から来ているらしい。 吹き替えという意味の方がオリジナルに近いようだ。ややこしいのであの頃の「ダビング」は忘れることにしよう。
この自動吹き替え、英語圏では勝手に有効化されて邪魔に思われていることが多いように見えるが、自分は非常に助かっている。 オートダビング版なら見たいという動画がたくさんある。 検索条件に音声トラックの対応言語を指定できるようにしてほしい。
Youtubeでオートダビング版を多く見るようになってから、オートダビングがまだ行われていない動画やPodcastを同じように聞こうとしている人はいないかと 「auto-dubbing」などで検索するようになった。 しかし軽く調べただけではピンとくるものは見つからなかった。 ある日、Faster-WhisperというツールのREADMEの"Community integrations"セクションに"Open-Dubbing"というツールが紹介されているのを見つけた。 まさに探しているものだと思い、試してみることにした。
SYSTRAN/faster-whisper: Faster Whisper transcription with CTranslate2
Open-Dubbingとは
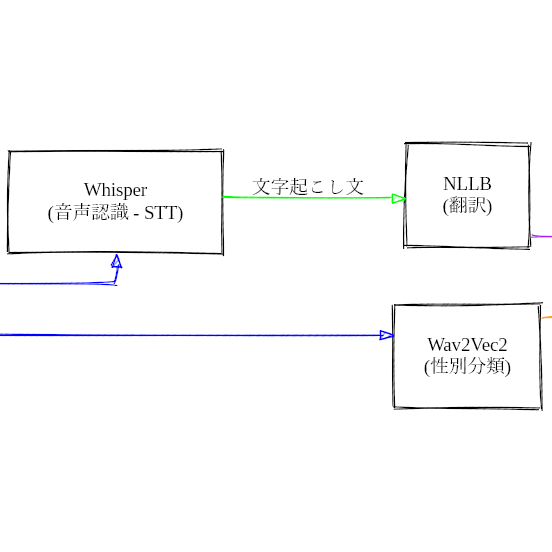
Open-Dubbingは、動画ファイルをもとに自動で吹き替え動画を生成するツールである。 音声抽出、話者分離、性別分類、音声認識、翻訳、音声合成のそれぞれでAIモデルを利用している。 各モデルは公開されているため、一連の処理はすべてローカルで完結する。

動かしてみる
とりあえず試してみるために、open-dubbingを動かすためのdevcontainerを用意した。
kotet/opendubbing-docker: Softcatala/open-dubbing で音声や動画の英日吹き替えをするための環境
以下の2つのPythonパッケージを利用する。
dependencies = [
"coqui-tts[ja]>=0.25.3",
"open-dubbing[coqui]>=0.2.3",
]
自分の環境では以下のようなオプションで動かすことができた。
uv run open-dubbing \
--target_language jpn \
--hugging_face_token $HUGGING_FACE_TOKEN \
--tts coqui \
--stt faster-whisper \
--vad \
--translator nllb \
--device cuda \
--device_pyannote cuda \
--cpu_threads 8 \
--nllb_model nllb-200-1.3B \
--whisper_model large-v3 \
--input_file "$INPUT_MP4" \
--output_directory output/ \
--log_level DEBUG \
--original_subtitles \
--dubbed_subtitles
オプション解説
これ以降、各オプションの選択について説明する。
target_language
吹き替え先の言語を指定する。 言語はISO 639-3のコードで指定する。 日本語は"jpn"、英語は"eng"である。なにも考えずに"ja_jp"などと指定するとエラーになる。
hugging_face_token
pyannoteという話者分離のモデルはライセンスが特殊で、同意と登録が必要になる。 登録したHugging Faceのアカウントのアクセストークンを指定する。
tts
音声合成に利用するモデルを指定する。mms,coqui,openai,edge,cli,apiのいずれかが指定できる。 そのうちローカルで動かせるのはmmsとcoquiである。 mmsは1000以上の言語に対応しているが日本語には対応していない。マイナー言語向けなんだろうか。
stt
auto,faster-whisper,transformersのいずれかを指定する。
faster-whisperとtransformersのいずれもWhisperモデルだ。
faster-whisperはCTranslate2を利用して最適化されたWhispertransformersはHugging FaceのTransformersライブラリを利用したWhisper。autoを指定するとMacOSの場合にこちらが選択されるようだ
vad
VAD (Voice Activity Detection)を有効にするかどうか。 faster-whisperの場合に利用可能で、無音区間で「チャンネル登録よろしくお願いします」みたいなハルシネーションが発生するのを軽減できるらしい。
translator
翻訳に利用するモデルを指定する。nllb,apertiumのいずれかが指定できる。 apertiumは外部でAPIサーバーを立てる必要がある。 逆に言うとapertium互換のAPIを用意すれば任意の翻訳エンジンを利用できる。 NLLB(No Language Left Behind)はMetaが公開している翻訳モデル。
device, device_pyannote
利用するデバイスを指定する。cpu,cudaのいずれかが指定できる。
cpu_threads
CPUを利用した推論を行う場合に利用するスレッド数を指定する。
nllb_model
nllb-200-1.3B,nllb-200-3.3Bのいずれかを指定する。
nllb-200-3.3Bを使いたいが、VRAMが17GBほど必要になるっぽい。
whisper_model
medium,large-v2,large-v3のいずれかを指定する。
Whisperの要求VRAMサイズは、largeで"~10 GB"とある
が、faster-whisperでは何割か削減される。
自分の持ってるGeForce RTX 4060 (8GB VRAM)ならlarge-v3も十分な速度で動かせた。
input_file
入力ファイルを指定する。動画ファイルはMP4形式である必要がある。
output_directory
出力先ディレクトリを指定する。中間ファイルが大量に生成されるし、出力も動画、音声、字幕と複数ファイルになるので、処理ごとにディレクトリを分けた方がよい。
log_level
ログレベルを指定する。
original_subtitles, dubbed_subtitles
元の字幕と翻訳字幕のsrtファイルを生成するかどうか。
自動化する
open-dubbingコマンド単体だと、自分の用途では不便な点がいくつかある。
- 複数のファイルをまとめて処理できない
- mp3ファイルを直接処理できない
- すでに処理したファイルをスキップしたい
- 入力ファイルに変な文字が入ってると勝手にリネームされる
これらを解決するために、同リポジトリにrun_open_dubbing.shというスクリプトを用意した。
これを使うと、inputディレクトリに入れたmp3やmp4ファイルをまとめて処理できる。
結果
実際に処理してみた結果、以下のような音声が得られた。
オリジナル: The server-side rendering equivalent for LLM inference workloads - Stack Overflow
活舌が悪い。 それだけならまだいいが、どうも長すぎるテキストは途中で切れてしまうようだ。 たとえば冒頭の導入セリフは以下のように41秒まであるが、25秒あたりで切れてしまっている。
1
00:00:09,177 --> 00:00:41,965
Hello, everyone, and welcome to the Stack Overflow podcast, a place to talk all things software and technology. I am your host, Ryan Donovan, and today we're talking about the AI infrastructure and inference workloads and how that's changing. And my guest today is Tuhin Srivastava, the CEO and co-founder of Base10. So welcome to the show, Tuhin. Thanks for having me. Love the show, and I'm excited to chat about all things AI Infra. Before we get into that, we like to get to know our guests before we get started. Could you tell us a little bit about how you got into software and technology?
1
00:00:09,177 --> 00:00:41,965
皆さん,こんにちは.そして,すべてのソフトウェアとテクノロジーの話をするために作られる スタック・オーバーフロー・ポッドキャストにようこそ. 私はあなたのホスト,ライアン・ドノヴァンです. 今日はAIのインフラストラクチャとインフェルエンスのワークロードについて,そしてそれがどのように変化しているかをお話しします. そして,今日のゲストは,Base10のCEO兼共同創設者,トゥヒン・スリヴァスタヴァです. 番組にようこそ,トゥヒン.私を招待してくれてありがとう. 番組が好きです.そして,私はAIのインフラについて話すのを楽しみにしています. その前に,私たちは,始めること前に,お客さんを知りたいと思います. あなたはソフトウェアとテクノロジーの分野にどのように入ったかについて少し話してくれますか?
妥協して小さいモデルを使っているせいか翻訳も怪しい。文字起こしは正常に動作しているが、翻訳は後半部分が全部"Lama 3,Lama 3,…“という繰り返しになってしまっている。 San Franciscoを"旧金山"と訳しているあたり、日本語と中国語の区別もついていないかもしれない。 しかも品質が悪いわりに処理に時間がかかる。たぶん処理のうち一番時間がかかっているのは翻訳っぽい。
55
00:14:59,181 --> 00:16:12,115
So that's a runtime component. And I think the other piece is the infrastructure component, which is like, there's a lot of problems that come with running GPUs. So like cloud redundancy is a big one where you need GPUs in different places. Access to capacity is important. Code starts, which is like, hey, I don't have a model ready. And I all of a sudden get a request, how fast can I spin up a model on a GPU? To do that, scaling up and down is important. Pulling compute is important. And so that's the infrastructure problem. So there's a runtime problem, an infrastructure problem, and then what we call a developer workflow problem, which is, it's really easy if I just want to use Lama 3.3 to think of this as a, give me Lama 3, an API for Lama 3.3. The truth is that in the enterprise, most companies have between three and 300 models they're running. And when you have between three and 300 models that are running, and they might be different forms of Lama's or Whispers or Orpheus's, you name it, or stuff they're training themselves or embeddings models, you need developer workflow around that. And so what we think about there is that, hey, observability matters, CICD matters, as really that whole DevOps stack to manage, this model with its runtime and its infrastructure. And they're the three pillars that we think about when we're running models in production, which is how fast can it run on a given chip? Now, how do you scale that across a bunch of different infrastructure? And then what does the tooling look like to manage that?
55
00:14:59,181 --> 00:16:12,115
実行時間の構成要素です. もう一つはインフラストラクチャの構成要素です. GPUの実行に伴う多くの問題があります. クラウドリドゥンデンスが大きな問題です. 異なる場所で GPUが必要になります. 容量へのアクセスが重要です. コードが起動します. モデルが準備されていないので,突然,私は, GPUでモデルをどれくらい速くスピニングできるかというリクエストを受けます. それには,スケーリングアップとダウンが重要です. 計算を重要視します. そして,インフラストラクチャの問題です. 実行時間の問題,インフラストラクチャの問題,そして開発者ワークフローの問題です. これは,私がこれをLama 3.3として考えるだけで,とても簡単です. Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama
今後の展望
今回はOpen-Dubbingをとりあえず動かせるように整備した。 しかし、英日吹き替えに使うにはまだまだ課題が多い。 今後、余裕があれば以下のようなことを試していきたい。
- 現状
--pyannote_device以外に処理別にデバイスを指定できないので、サイズの大きな翻訳モデルだけCPUで動かすといったことができない。Pull Requestを送ってみたい - 翻訳モデルをいろいろ試す。ローカルではPlaMoを使ってみたい。ダメそうならGoogle翻訳API等を接続できるようにしてみる
- 音声合成モデルをいろいろ試す
- Googleに翻訳と音声合成のAPIがあって無料枠もある。いろいろ試す労力が割けなかったら一旦全部Googleにオフロードしてみる手もあるかも