Overview
I recently tried out Open-Dubbing, a tool that automatically generates Japanese voice-overs for videos. This article provides an overview of Open-Dubbing and explains how to use it, along with introducing a custom wrapper script I developed. While I was able to make it work in my environment, I’m still dissatisfied with its performance. I’ve also included audio samples from actual execution to demonstrate the user experience.
Background
For quite some time, I’ve been experimenting with various methods to make English-language videos and podcasts more accessible. While many contents are available with transcripts or subtitles, the viewing barrier remains relatively high. There are plenty of contents that are just not worth the effort of keeping my eyes engaged, and since I often have time when only my ears are free, I’d much rather listen passively.
For instance, I’ve heard President Trump appears on various podcasts and would like to give it a try—but it’s not worth holding my phone up to my face while following subtitles. If I could simply understand native English speakers, there would be no problem, but unfortunately my listening skills aren’t sharp enough to accurately pick up useful information just by hearing it… Recently, I’ve been using NotebookLM to process mp3 files and listen to brief summaries through its “Podcast Generation” feature. But this approach inevitably misses a lot of content.
By the way, when watching YouTube recently, I started noticing videos marked with an “Auto-Dubbing Version” label. …Upon further searching, I can’t seem to find any such videos anymore. Maybe they were removed because auto-dubbing wasn’t popular enough in English-speaking regions. Anyway, there used to be this display feature. At first, I wondered what it meant—I thought it might be referring to “dubbing” as in copying TV recordings to DVDs—but it actually stands for “auto-dubbing,” meaning automatically generated voice-overs.
While researching for this blog post, I discovered that the original meaning of “dubbing” (as in dubbing) also comes from this same word. It seems the dubbing meaning is closer to the original usage. Considering how confusing this is, I’ll just forget about that earlier “dubbing” terminology.
Regarding this auto-dubbing, it appears to automatically activate in English-speaking regions and is often viewed as annoying—but I find it to be incredibly helpful. There are so many videos I’d specifically want to watch in their auto-dubbing version. I wish YouTube allowed users to specify target language options for audio tracks in their search filters.
Since I started seeing more auto-dubbing versions on YouTube, I’ve been wondering if there are other people who also want to listen to videos or podcasts that haven’t yet been auto-dubbed, so I’ve been searching for terms like “auto-dubbing.” However, after a brief search, I couldn’t find any particularly promising results.
One day, I stumbled upon the “Open-Dubbing” tool mentioned in the “Community integrations” section of the README for Faster-Whisper. Seeing this was exactly what I was looking for, I decided to give it a try.
SYSTRAN/faster-whisper: Faster Whisper transcription with CTranslate2
What is Open-Dubbing?
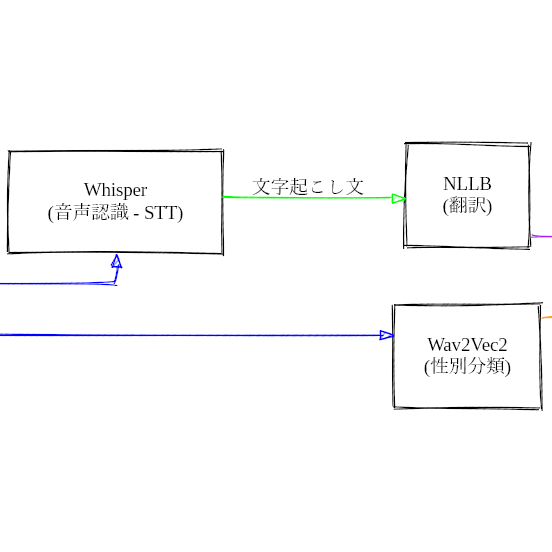
Open-Dubbing is a tool designed to automatically generate dubbed versions of video files. It utilizes AI models for various processes including: audio extraction, speaker separation, gender classification, speech recognition, translation, and text-to-speech synthesis. All these models are publicly available, allowing the entire process to be completed locally.

Setting it up and running
To get started quickly, I prepared a devcontainer environment to run open-dubbing.
The following two Python packages are utilized:
dependencies = [
"coqui-tts[ja]>=0.25.3",
"open-dubbing[coqui]>=0.2.3",
]
In my environment, I was able to run the tool with the following options:
uv run open-dubbing \
--target_language jpn \
--hugging_face_token $HUGGING_FACE_TOKEN \
--tts coqui \
--stt faster-whisper \
--vad \
--translator nllb \
--device cuda \
--device_pyannote cuda \
--cpu_threads 8 \
--nllb_model nllb-200-1.3B \
--whisper_model large-v3 \
--input_file "$INPUT_MP4" \
--output_directory output/ \
--log_level DEBUG \
--original_subtitles \
--dubbed_subtitles
Option explanations
Below are detailed explanations for each configuration option.
target_language
Specifies the target language for dubbing. Languages must be specified using ISO 639-3 codes. Japanese is “jpn”, English is “eng”. Attempting to specify “ja_jp” without understanding the requirements will result in an error.
hugging_face_token
The pyannote speaker separation model has unique licensing requirements that require agreement and registration. Specify the access token for your registered Hugging Face account.
tts
Specifies the text-to-speech model to use. Acceptable values include mms, coqui, openai, edge, cli, or api. Locally executable options are mms and coqui. mms supports over 1000 languages but does not support Japanese - presumably designed for lesser-used languages.
stt
Specifies either auto, faster-whisper, or transformers.
Both faster-whisper and transformers use Whisper models.
faster-whisper: Whisper optimized using CTranslate2transformers: Whisper implemented using Hugging Face’s Transformers library. Whenautois specified, this option appears to be selected on MacOS systems.
vad
Enables Voice Activity Detection (VAD). Available when using faster-whisper, this feature helps reduce hallucinations like “Please subscribe to our channel” occurring during silent intervals.
translator
Specifies the translation model to use. Acceptable values include nllb or apertium. apertium requires setting up an external API server. Conversely, any translation engine compatible with apertium’s API interface can be used. NLLB (No Language Left Behind) is a translation model published by Meta.
device, device_pyannote
Specifies the target device for processing. Acceptable values include cpu or cuda.
cpu_threads
Specifies the number of threads to use when performing CPU-based inference.
nllb_model
Specifies either nllb-200-1.3B or nllb-200-3.3B models.
While nllb-200-3.3B is available, it requires approximately 17GB of VRAM.
whisper_model
Specifies either medium, large-v2, or large-v3 models.
Whisper’s VRAM requirements are listed as “~10 GB” for the large model
However, faster-whisper reduces this requirement by a significant margin.
Even with my GeForce RTX 4060 (8GB VRAM), large-v3 runs at sufficient speed.
input_file
Specifies the input file. Video files must be in MP4 format.
output_directory
Specifies the output directory. Since numerous intermediate files are generated and outputs include multiple file types (video, audio, subtitles), it’s advisable to separate processing by directory.
log_level
Specifies the log level.
original_subtitles, dubbed_subtitles
Specifies whether to generate SRT files for original and translated subtitles.
Automation
The open-dubbing command alone has some limitations that make it unsuitable for my specific use cases:
- Cannot process multiple files simultaneously
- Cannot directly process MP3 files
- Cannot skip files that have already been processed
- Input files containing unusual characters are automatically renamed
To address these limitations, I’ve included a script called run_open_dubbing.sh in the same repository.
Using this script allows you to batch process MP3 and MP4 files placed in the input directory.
Results
After actual processing, the following audio was obtained:
Original: The server-side rendering equivalent for LLM inference workloads - Stack Overflow
The pronunciation is somewhat unclear. Even this isn’t the worst problem, but it seems that excessively long text gets truncated mid-sentence. For instance, the opening introductory dialogue runs for 41 seconds in total, but gets cut off around 25 seconds.
1
00:00:09,177 --> 00:00:41,965
Hello, everyone, and welcome to the Stack Overflow podcast, a place where we discuss all things software and technology. I am your host, Ryan Donovan, and today we're talking about AI infrastructure and inference workloads, and how this landscape is evolving. And my guest today is Tuhin Srivastava, the CEO and co-founder of Base10. So welcome to the show, Tuhin. Thanks for having me. I love the show, and I'm excited to discuss all things AI infrastructure. Before we dive into that, we like to get to know our guests before we begin. Could you tell us a bit about how you entered the world of software and technology?
1
00:00:09,177 --> 00:00:41,965
皆さん,こんにちは.そして,すべてのソフトウェアとテクノロジーの話題を扱う スタック・オーバーフロー・ポッドキャストへようこそ. 私は司会のライアン・ドノヴァンです. 今日はAIのインフラストラクチャと推論ワークロードについて,そしてそれらがどのように変化しているかをお話しします. そして本日のゲストは,Base10のCEO兼共同創業者であるトゥヒン・スリヴァスタヴァ氏です. 番組にようこそ,トゥヒン. 私をお招きいただき感謝します. この番組が大好きです.そして,AIインフラストラクチャについて話すのを楽しみにしています. その前に,私たちは番組を始める前にゲストの方について少し知りたいと思います. あなたはどのようにしてソフトウェアとテクノロジーの分野に足を踏み入れたのか,少しお話しいただけますか?
翻訳は妥協したせいか少し怪しい部分があります。文字起こし自体は正常に機能していますが,翻訳部分は後半部分がすべて"Lama 3,Lama 3,…“という繰り返しになってしまっています。 San Franciscoを"旧金山"と訳している箇所を見ると,日本語と中国語の区別もついていない可能性があります。 しかも品質の割に処理時間が長くかかります。おそらく処理の中で最も時間がかかっているのは翻訳部分のようです。
55
00:14:59,181 --> 00:16:12,115
これはランタイムコンポーネントに関する話です。そしてもう1つの重要な要素はインフラストラクチャコンポーネントです。GPUを運用する際には多くの課題があります。例えばクラウド冗長性は重要な課題の一つで、異なる場所にGPUを配置する必要があります。計算リソースへのアクセスも重要です。コードの起動、つまり「モデルが準備できていない状態で、突然GPU上でモデルを起動する必要が生じた場合、どれほど迅速に対応できるか」といった問題もあります。これに対応するにはスケールアップ/ダウン機能が不可欠です。計算リソースの割り当ても重要です。つまりこれがインフラストラクチャの課題なのです。ランタイムの問題、インフラストラクチャの問題、そして私たちが「開発者ワークフロー問題」と呼んでいるものがあります。これはLama 3.3を単に「Lama 3を提供してください」というAPIとして考える場合は非常に簡単です。しかし実際には、企業では通常3~300種類のモデルを運用しています。3~300種類のモデルが稼働している場合、それらがLamaやWhispers、Orpheusなどの異なるバージョンであったり、自社でトレーニングしたモデルや埋め込みモデルであったりする可能性があります。このような状況では、適切な開発者ワークフローが必要となります。私たちがここで重視しているのは、可観測性、CI/CD、そしてこのモデルとそのランタイムおよびインフラストラクチャを管理するためのDevOpsスタック全体です。これらは本番環境でモデルを運用する際に考慮すべき3つの柱です。具体的には、特定のチップ上でどれほど迅速に実行できるかという問題です。次に、この処理を複数の異なるインフラストラクチャに拡張する方法です。そして最後に、このような環境を管理するためのツール群がどのようなものであるかという点です。
55
00:14:59,181 --> 00:16:12,115
これは実行時コンポーネントに関する話です。もう1つの重要な要素はインフラストラクチャコンポーネントです。GPUの運用には多くの課題が伴います。クラウド冗長性は主要な課題の一つで、異なる場所にGPUを配置する必要があります。計算リソースへのアクセスも重要です。コードの起動、つまり「モデルが準備できていない状態で、突然GPU上でモデルをどれほど迅速に起動できるかという要求があった場合」に対応する必要があります。これにはスケールアップ/ダウン機能が不可欠です。計算リソースの割り当ても重要です。これはインフラストラクチャの課題です。ランタイムの問題、インフラストラクチャの問題、そして開発者ワークフローの問題があります。これは「Lama 3.3として考えるだけで非常に簡単です」という意味です。Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3、Lama 3
Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3,Lama 3
Future Development Plans
In this iteration, we have successfully implemented Open-Dubbing in a functional state. However, several key challenges remain before it can be used effectively for English-to-Japanese dubbing. With additional time available, we plan to explore and implement the following features:
- Currently, only the
--pyannote_deviceoption allows specifying processing devices for each task. This limitation prevents flexible configurations like running only large-scale translation models on CPU. We intend to submit a pull request to propose improvements. - Experiment with various translation model variants. For local testing, we plan to experiment with PlaMo. If this proves challenging, we may also consider integrating connections to services like Google Translate API.
- Test different variants of speech synthesis models.
- Google provides both translation and speech synthesis APIs, with free usage tiers. If we’re unable to dedicate sufficient time to experimenting with various features, offloading all processing to Google could serve as a viable alternative approach.