This article documents my experience creating the “Ministry of Internal Affairs and Communications News & Updates AI Bot” (@micsummary@mastodon.kotet.jp). This Mastodon bot monitors the Ministry of Internal Affairs and Communications’ RSS feed for new announcements and automatically summarizes any attached PDF documents before posting them to Mastodon. For example, it generates posts like this one—a summary of a recent conference regarding undersea cable infrastructure that has recently made news.
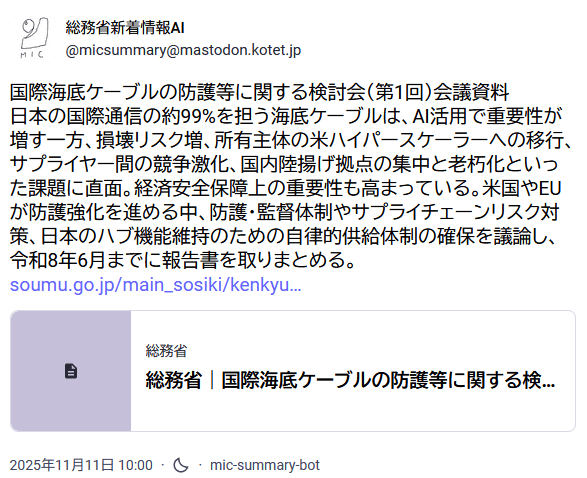
Since I approached this project with the philosophy of “minimal investment, no overexertion,” the development process took much longer than expected. However, for those interested in creating similar bots, I’ll share some particularly interesting aspects of this project.
Why I Created This Bot
The Ministry of Internal Affairs and Communications’ website provides its news updates via RSS feed. Essentially, it includes press releases issued by the ministry and information about meetings related to new policy initiatives, along with any accompanying documents and meeting minutes. However, the news updates are almost exclusively provided in PDF format, requiring users to open the files to read the content.
Ministry of Internal Affairs and Communications | About RSS Distribution
The press releases are particularly problematic—some contain nothing more than a single sentence of text on a single PDF page. While I understand that press releases prioritize timeliness over elaborate design, they should really move beyond PDFs and strive for greater efficiency. Is there some legal requirement that public documents must be printable in identical format for everyone?
I follow the news updates out of curiosity to see how the government operates efficiently, but I’m not particularly interested in sitting in front of a large device just to read PDFs. That’s why I decided to create an LLM-based bot that summarizes PDF content and posts it to Mastodon. Since Mastodon accounts can also be used as RSS feeds, by subscribing to this feed, you can easily check the Ministry of Internal Affairs and Communications’ news updates in a format that’s more accessible from mobile devices.
Bot Architecture
This bot utilizes LLM in two main functional areas:
- A component that determines whether a given page warrants summarization
- A component that actually reads PDF or page content and generates summaries
This article focuses specifically on the more complex summarization generation aspect. The decision-making component follows similar fundamental principles.
I’ll proceed by listing my ideas without overly organizing them.
Technologies Used in Development
I own a Raspberry Pi Zero W that runs continuously at home. Since a monorepo-style server application written in Go already runs on this Raspberry Pi, I implemented the bot as a Go library that can be integrated into this existing system.
For bot development, I used Gemini Code Assist. However, even with the current performance levels and free usage limits, the coding assistance wasn’t sufficient for larger projects. As the repository grew in size, progress became nearly impossible. Consequently, about 70% of the code was written manually by myself.
LLM Service and Model Selection
For the bot’s summarization generation, I utilized Google’s Gemini. Google’s API offers generous free usage limits, and Gemini provides more than sufficient free quota for even basic bot development needs.
At the time of bot creation, both gemini-2.5-pro and gemini-2.5-flash were available. While gemini-2.5-flash could generate reasonably accurate summaries, switching to gemini-2.5-pro made a significant improvement - it went beyond just generating overall summaries and began effectively identifying and highlighting the “most interesting” content.
It’s important to note that free usage limits (free tier rate limits) aren’t stable and can suddenly change. When starting bot development, the API rate limits were documented, but due to frequent changes, they were later removed from the documentation and are now only visible through the dashboard. Still, I’m grateful that any free usage is available at all.
I was using gemini-2.5-pro for summarization when suddenly the free quota was discontinued, causing the bot to fail with ResourceExhausted errors.
Additionally, the gemini-2.0-flash model, which was used for content screening, also seems to have been discontinued. Currently, we’re operating using a combination featuring gemini-2.5-flash and gemini-2.5-flash-lite. As long as LLM performance continues to improve, even with reduced free quotas, the increased capabilities might offset the limitations. However, it’s also important to design systems in a way that doesn’t rely too heavily on model performance, in case free quotas are completely discontinued or the free models’ capabilities degrade over time.
Structured Output
What is Structured Output?
Our LLM outputs utilize structured output functionality. This feature formats the LLM’s responses according to a predefined schema. Unlike simply instructing the prompt in this manner, it operates during the response generation process itself, effectively eliminating the probability of generating tokens that would result in output not conforming to the schema.
In other words, even LLMs that struggle to produce valid JSON by default can reliably generate JSON that perfectly matches the schema—with absolute certainty—when using structured output.
Of course, the quality of content beyond what’s expressed in the schema still depends on LLM performance, so whether the generated output is valuable remains a separate consideration. Nonetheless, the fact that the output format is guaranteed makes it highly compatible with automation systems.
I heard about a method that uses structured output to create Chain-of-Thought processes, enabling even low-performance models without meta-cognitive capabilities to effectively implement Chain-of-Thought reasoning. We’ve been testing this approach.
Summary Generation Schema
The code below represents the actual structured output schema definition for summary generation used in our current bot implementation. It consists of five main components:
modelConfig := &genai.GenerateContentConfig{ Temperature: new(float32), // 0 ResponseMIMEType: “application/json”, ResponseSchema: &genai.Schema{ Type: genai.TypeObject, Properties: map[string]*genai.Schema{ “documents”: { Type: genai.TypeArray, Items: &genai.Schema{ Type: genai.TypeObject, Properties: map[string]*genai.Schema{ “metadata”: { Type: genai.TypeString,
By enforcing this structured output format that progressively generates summaries, we aim to encourage LLMs to produce shorter, more refined summaries.
modelConfig := &genai.GenerateContentConfig{
Temperature: new(float32), // 0
ResponseMIMEType: "application/json",
ResponseSchema: &genai.Schema{
Type: genai.TypeObject,
Properties: map[string]*genai.Schema{
"documents": {
Type: genai.TypeArray,
Items: &genai.Schema{
Type: genai.TypeObject,
Properties: map[string]*genai.Schema{
"metadata": {
Type: genai.TypeString,
},
"keyPoints": {
Type: genai.TypeArray,
Items: &genai.Schema{
Type: genai.TypeString,
},
},
"summary": {
Type: genai.TypeString,
},
},
PropertyOrdering: []string{"metadata", "keyPoints", "summary"},
},
},
"first_summary": {
Type: genai.TypeString,
},
"omissibles": {
Type: genai.TypeArray,
Items: &genai.Schema{
Type: genai.TypeString,
},
},
"missed_items": {
Type: genai.TypeArray,
Items: &genai.Schema{
Type: genai.TypeString,
},
},
"final_summary": {
Type: genai.TypeString,
},
},
PropertyOrdering: []string{"documents", "first_summary", "omissibles", "missed_items", "final_summary"},
Required: []string{"final_summary"},
},
}
The input prompt can be written in standard natural language. Below is an excerpt from it (translated). I’ve structured the key names directly in bullet points to match the instructions and outputs, though even highly sophisticated models might not need such explicit structuring.
【Document Summary Output Format】
- metadata: Metadata including title, date/time, attendees, location, agenda, etc.
- keyPoints: List of 3-5 key statements or decisions
- summary: Concise Japanese summary of the document's main points
【Primary Summary Output Format】
- first_summary: Focuses on particularly important parts of the meeting, written in the "da/dearu" style, with 3-5 sentences totaling approximately 200 characters in Japanese
【Improvement Suggestions Output Format】
- omissibles: Information that doesn't need to be included in the summary (e.g., already contained in the title) or duplicated information that can be consolidated into a single entry in the primary summary
- missed_items: Keywords representing important facts or decisions that aren't included in the primary summary
【Final Summary Output Format】
- final_summary: Focuses on particularly important parts of the meeting, written in the "da/dearu" style, with 3-5 sentences totaling approximately 200 characters in Japanese. If space remains after truncation, important information should be added based on missed_items to enhance comprehensiveness
Results
The output would resemble the following. Since I believe human-readable summaries should include some interpretive commentary when presenting data of sufficient length, I’ll provide a brief explanation.
The FirstSummary is a summary generated immediately after processing the Documents, and it successfully captures the most critical points like “As a result, no modifications were made to the proposal based on submitted opinions.”
However, it fails to note specific topics such as “what types of opinions were received” or “how the Ministry of Internal Affairs and Communications responded to them.”
The MissedItems identifies topics absent from the primary summary, including content about “pay-per-use gaming systems and Super Chat.”
These represent new concepts among the opinions and include particularly interesting material—like the newsworthy statement “Super Chat isn’t included in the Consumer Price Index”—that would make compelling headlines.
The FinalSummary effectively incorporates this content, resulting in a more comprehensive summary.
This demonstrates the effectiveness of the staged summarization process through structured output.
micsummarybot.SummarizeResult{
Documents:[]micsummarybot.DocumentSummary{
micsummarybot.DocumentSummary{
Summary:"総務省は、令和7年7月31日から9月5日に実施した「消費者物価指数2025年基準改定計画(案)」に関する意見募集の結果を公表した。11件の意見が寄せられ、それらに対する総務省の考え方が示された。今後のスケジュールとして、本年中に2025年基準改定計画を決定し、令和8年(2026年)7月分の消費者物価指数公表時に2025年基準指数への切り替えを予定している。",
Metadata:"報道資料 「消費者物価指数2025年基準改定計画(案)」についての意見募集の結果 令和7年10月16日",
KeyPoints:[]string{"総務省は「消費者物価指数2025年基準改定計画(案)」に対する意見募集結果を公表した。", "令和7年7月31日から9月5日まで意見募集を実施し、11件の意見を受領した。", "提出された意見とそれに対する総務省の考え方を公表した。", "2025年基準改定計画は本年中に決定され、令和8年(2026年)7月分の消費者物価指数公表時に2025年基準指数へ切り替え予定である。"}
},
micsummarybot.DocumentSummary{
Summary:"「消費者物価指数2025年基準改定計画(案)」に対する意見募集で寄せられた11件の意見と、それに対する総務省の考え方が示された。意見は品目選定、調査方法、名称変更など多岐にわたるが、総務省は既存の選定基準や統計作成上の基本方針に基づき、各意見への対応を説明。新たな品目追加の要望については、基準適合状況に応じて検討する方針を示し、都度課金型ゲームやスーパーチャットは対象外とした。家賃の品質調整は今後も検討を進める。結果として、提出意見を踏まえた案の修正は行われなかった。",
Metadata:"「消費者物価指数2025年基準改定計画(案)」に対して提出された御意見及び総務省の考え方 (令和7年7月31日~同年9月5日意見募集) 別紙",
KeyPoints:[]string{"意見募集で寄せられた11件の意見に対し、総務省は既存の品目選定基準や調査方針に基づき回答した。", "「充電料」「充填料」やフードデリバリー、有線イヤホンなど、新たな品目追加の要望は、今後の基準適合状況に応じて検討される。", "都度課金型ゲームやスーパーチャットは、品質継続調査の困難さや所得移転の性格から消費者物価指数の対象外とされた。", "「ノンアルコールビール」の名称変更や「サッカー観戦料」等の廃止は、品目概念の明確化や選定基準に基づき適切と判断された。", "家賃の品質調整については、重要性を鑑み、今後も実証的な研究分析と検討を進める方針である。", "提出された意見を踏まえた案の修正は行われなかった。"}
}
},
FirstSummary:"総務省は意見募集結果を公表した。11件の意見が寄せられたが、総務省は既存の品目選定基準や統計作成方針に基づき回答し、案の修正は行われなかった。本年中に改定計画を決定し、2026年7月分の消費者物価指数公表時に2025年基準指数へ切り替える予定。",
Omissibles:[]string{"「消費者物価指数2025年基準改定計画(案)」についての意見募集の結果", "令和7年10月16日", "意見募集期間", "意見数", "総務省が意見募集を実施したこと"},
MissedItems:[]string{"都度課金型ゲームやスーパーチャットが消費者物価指数の対象外である理由(品質継続調査の困難さ、所得移転の性格)", "家賃の品質調整に関する今後の検討方針"},
FinalSummary:"総務省は意見募集結果を公表。寄せられた11件の意見に対し、既存の品目選定基準や統計作成方針に基づき回答し、案の修正は行われなかった。都度課金型ゲームやスーパーチャットは品質継続調査の困難さや所得移転の性格から対象外とされた。家賃の品質調整は今後も実証的な研究分析と検討を進める。本年中に改定計画を決定し、2026年7月分の消費者物価指数公表時に2025年基準指数へ切り替える予定。"
}
API Call Testing
As a test, I wrote unit tests including model calls using an actual API key. For screening, we prepared both articles intended for summarization and those not intended for summarization to verify correct classification. For summarization generation, as automated verification is challenging, we manually reviewed the generated summaries. Although we introduced this later, being able to easily execute tests like this proved quite convenient.
$ make test-full
go test -v -tags=integration ./...
// ...omitted...
=== RUN TestSummarizeDocument
=== RUN TestSummarizeDocument/Summarize_page_with_one_PDF
time=2025-12-13T16:29:20.496+09:00 level=INFO msg="Starting document summarization process"
time=2025-12-13T16:29:20.496+09:00 level=INFO msg="Processing documents for download" count=1
time=2025-12-13T16:29:20.496+09:00 level=INFO msg="Downloading PDF file" url=../resources/example_for_summerize/001034183.pdf local_path=/tmp/TestSummarizeDocument3573160111/001/b89950ed-ecd4-4962-ab06-a2f0751ca245.pdf
time=2025-12-13T16:29:23.412+09:00 level=INFO msg="Starting Gemini API calls with retry" max_retry=4
summarizer_integration_test.go:120: Generated Summary: micsummarybot.SummarizeResult{Documents:[]micsummarybot.DocumentSummary{micsummarybot.DocumentSummary{Summary:"総務省は、令和7年7月31日から9月5日に実施した「消費者物価指数2025年基準改定計画(案)」に関する意見募集の結果を公表した。11件の意見が寄せられ、それらに対する総務省の考え方が示された。今後のスケジュールとして、本年中に2025年基準改定計画を決定し、令和8年(2026年)7月分の消費者物価指数公表時に2025年基準指数への切り替えを予定している。", Metadata:"報道資料 「消費者物価指数2025年基準改定計画(案)」についての意見募集の結果 令和7年10月16日", KeyPoints:[]string{"総務省は「消費者物価指数2025年基準改定計画(案)」に対する意見募集結果を公表した。", "令和7年7月31日から9月5日まで意見募集を実施し、11件の意見を受領した。", "提出された意見とそれに対する総務省の考え方を公表した。", "2025年基準改定計画は本年中に決定され、令和8年(2026年)7月分の消費者物価指数公表時に2025年基準指数へ切り替え予定である。"}}, micsummarybot.DocumentSummary{Summary:"「消費者物価指数2025年基準改定計画(案)」に対する意見募集で寄せられた11件の意見と、それに対する総務省の考え方が示された。意見は品目選定、調査方法、名称変更など多岐にわたるが、総務省は既存の選定基準や統計作成上の基本方針に基づき、各意見への対応を説明。新たな品目追加の要望については、基準適合状況に応じて検討する方針を示し、都度課金型ゲームやスーパーチャットは対象外とした。家賃の品質調整は今後も検討を進める。結果として、提出意見を踏まえた案の修正は行われなかった。", Metadata:"「消費者物価指数2025年基準改定計画(案)」に対して提出された御意見及び総務省の考え方 (令和7年7月31日~同年9月5日意見募集) 別紙", KeyPoints:[]string{"意見募集で寄せられた11件の意見に対し、総務省は既存の品目選定基準や調査方針に基づき回答した。", "「充電料」「充填料」やフードデリバリー、有線イヤホンなど、新たな品目追加の要望は、今後の基準適合状況に応じて検討される。", "都度課金型ゲームやスーパーチャットは、品質継続調査の困難さや所得移転の性格から消費者物価指数の対象外とされた。", "「ノンアルコールビール」の名称変更や「サッカー観戦料」等の廃止は、品目概念の明確化や選定基準に基づき適切と判断された。", "家賃の品質調整については、重要性を鑑み、今後も実証的な研究分析と検討を進める方針である。", "提出された意見を踏まえた案の修正は行われなかった。"}}}, FirstSummary:"総務省は意見募集結果を公表した。11件の意見が寄せられたが、総務省は既存の品目選定基準や統計作成方針に基づき回答し、案の修正は行われなかった。本年中に改定計画を決定し、2026年7月分の消費者物価指数公表時に2025年基準指数へ切り替える予定。", Omissibles:[]string{"「消費者物価指数2025年基準改定計画(案)」についての意見募集の結果", "令和7年10月16日", "意見募集期間", "意見数", "総務省が意見募集を実施したこと"}, MissedItems:[]string{"都度課金型ゲームやスーパーチャットが消費者物価指数の対象外である理由(品質継続調査の困難さ、所得移転の性格)", "家賃の品質調整に関する今後の検討方針"}, FinalSummary:"総務省は意見募集結果を公表。寄せられた11件の意見に対し、既存の品目選定基準や統計作成方針に基づき回答し、案の修正は行われなかった。都度課金型ゲームやスーパーチャットは品質継続調査の困難さや所得移転の性格から対象外とされた。家賃の品質調整は今後も実証的な研究分析と検討を進める。本年中に改定計画を決定し、2026年7月分の消費者物価指数公表時に2025年基準指数へ切り替える予定。"}
--- PASS: TestSummarizeDocument (39.22s)
--- PASS: TestSummarizeDocument/Summarize_page_with_one_PDF (39.22s)
PASS
ok github.com/kotet/mic-summary-bot/mic_summary_bot 47.154s
Conclusion
The idea of creating a bot, deploying it, and writing a blog post about it had been in my plans for a long time, but it took much longer than expected. While this particular use case (“summarizing confusing RSS feeds”) is applicable to various scenarios beyond just the Ministry of Internal Affairs, such a bot can now be operated at no cost. By utilizing each platform’s free tiers, I encourage everyone to try creating their own information summarization bots.