D言語くん Advent Calendar 2017 11日めの記事。 空いていたので登録した。
ところでDeepAAというものがある。
これはD言語くんと組み合わせねばなるまい。
準備
まずはPythonとそのパッケージを用意する。 バージョンに気をつけよう。
$ python -V
Python 3.6.0
$ pip freeze
bleach==1.5.0
h5py==2.7.1
html5lib==0.9999999
Keras==2.0.8
Markdown==2.6.10
numpy==1.13.3
olefile==0.44
pandas==0.18.0
Pillow==4.2.1
protobuf==3.5.0.post1
python-dateutil==2.6.1
pytz==2017.3
PyYAML==3.12
scipy==1.0.0
six==1.11.0
tensorflow==1.3.0
tensorflow-tensorboard==0.1.8
Werkzeug==0.13
OsciiArt/DeepAAをクローンしてくる。
$ git clone https://github.com/OsciiArt/DeepAA.git
$ cd DeepAA/
weight.hdf5をREADME.mdのリンクからダウンロードしてDeepAA/model 下に配置。
700メガバイトくらいある。
D言語くんの画像を用意する。 そしてあれやこれや加工してできた画像がこちらである。
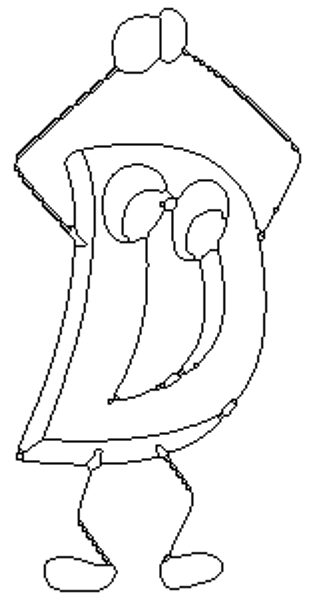
ちょっと雑すぎる気がするが気にしない。
画像をdman/d-man.pngとして配置し、それに合わせてoutput.pyを書き換える。
# parameters
model_path = "model/model.json" # or "model/model_light.json"
weight_path = "model/weight.hdf5" # or "model/weight_light.json"
-image_path = 'sample images/original images/21 original.png' # put the path of the image that you convert.
+image_path = 'dman/d-man.png' # put the path of the image that you convert.
new_width = 0 # adjust the width of the image. the original width is used if new_width = 0.
input_shape = [64, 64, 1]
実行
あとは実行するだけである。 Web上で実行できるくらいなので時間はかからない。
DeepAA$ python output.py
Using TensorFlow backend.
2017-12-13 19:53:47.858017: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2017-12-13 19:53:47.858047: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2017-12-13 19:53:47.858055: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
model load done
len(char_list) 899
class index of 1B space: 1
len(char_dict) 7484
converting: 0
converting: 1
converting: 2
converting: 3
converting: 4
converting: 5
converting: 6
converting: 7
converting: 8
converting: 9
converting: 10
converting: 11
converting: 12
converting: 13
converting: 14
converting: 15
converting: 16
converting: 17
そうしてoutput/にテキストと画像が出力される。
結果
最終結果がこちらである: d-man_w319_slide17.txt
しかし閲覧環境が多様の現在、AAを正しく見られる人のほうが少ないだろう。 実際自分の環境では新しくフォントを導入しないと崩れてしまう。 幸いなことに描画結果も同時に出力されるのでそちらを貼ろうと思う。
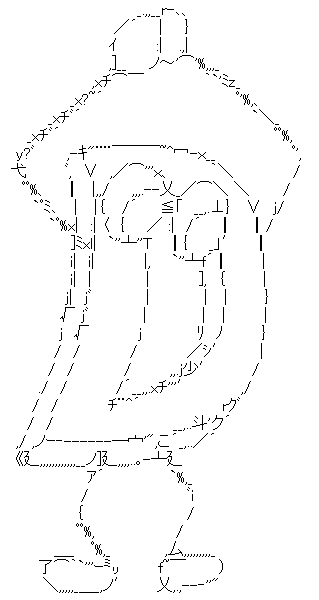
感想
入力の質の割にいい感じの結果になったのではないかと思う。
最初うまくいったらprogressに導入しようかと思っていた。 しかしこれはMS Pゴシックに最適化されたAAのため当然ターミナル上では崩れてしまう。
AAの定義からいけば別に最終的なフォーマットが画像でも何の問題もないのだが、そうするとわざわざ文字で構成する必要性というのがなくなってくる。 複数環境に対応できたものを除き、AAはもはや守らねば忘れ去られてしまう伝統芸能のような印象がある。 プロポーショナルフォントを使った複雑なAAはタイプライターでやってた頃のレベルまで衰退していく運命にあるのだろうなと思うと少し寂しくなった。